The Art of Agent Autonomy
Everyone's building agents. Almost nobody is asking the question that determines whether those agents succeed or spectacularly fail: how much autonomy should this particular agent actually have?
The gap between "impressive demo" and "production disaster" almost always comes down to one miscalibration — the agent had more freedom than the use case could safely support. Or not enough freedom, and humans became the bottleneck that killed the ROI.
The Autonomy Question Nobody's Asking
The word "agent" is being slapped on everything from a chatbot with RAG to a multi-agent system that autonomously initiates medical interventions. These are fundamentally different systems requiring fundamentally different infrastructure. But we talk about them like they're the same thing.
Here's the reality: only 21% of enterprises meet full AI readiness criteria as of 2026. Most teams are building basic assistive agents but aspiring to fully autonomous systems — without the guardrails, monitoring, or evaluation frameworks that make autonomy safe.
The autonomous vehicle industry learned this lesson a decade ago. SAE J3016 gave them six clearly defined levels — from "no automation" to "full automation" — with specific criteria for each. The result? Engineers, regulators, and executives all spoke the same language about what a car could and couldn't do at each level.
The AI agent industry doesn't have that shared vocabulary yet. And the cost of getting it wrong cuts both ways. Over-autonomous agents create blast radius — the refund bot that approves $14,000 without authority, the scheduling system that cancels appointments without checking dependencies. Under-autonomous agents leave value on the table — the triage assistant that could handle 80% of intake autonomously but requires a nurse to approve every single field.
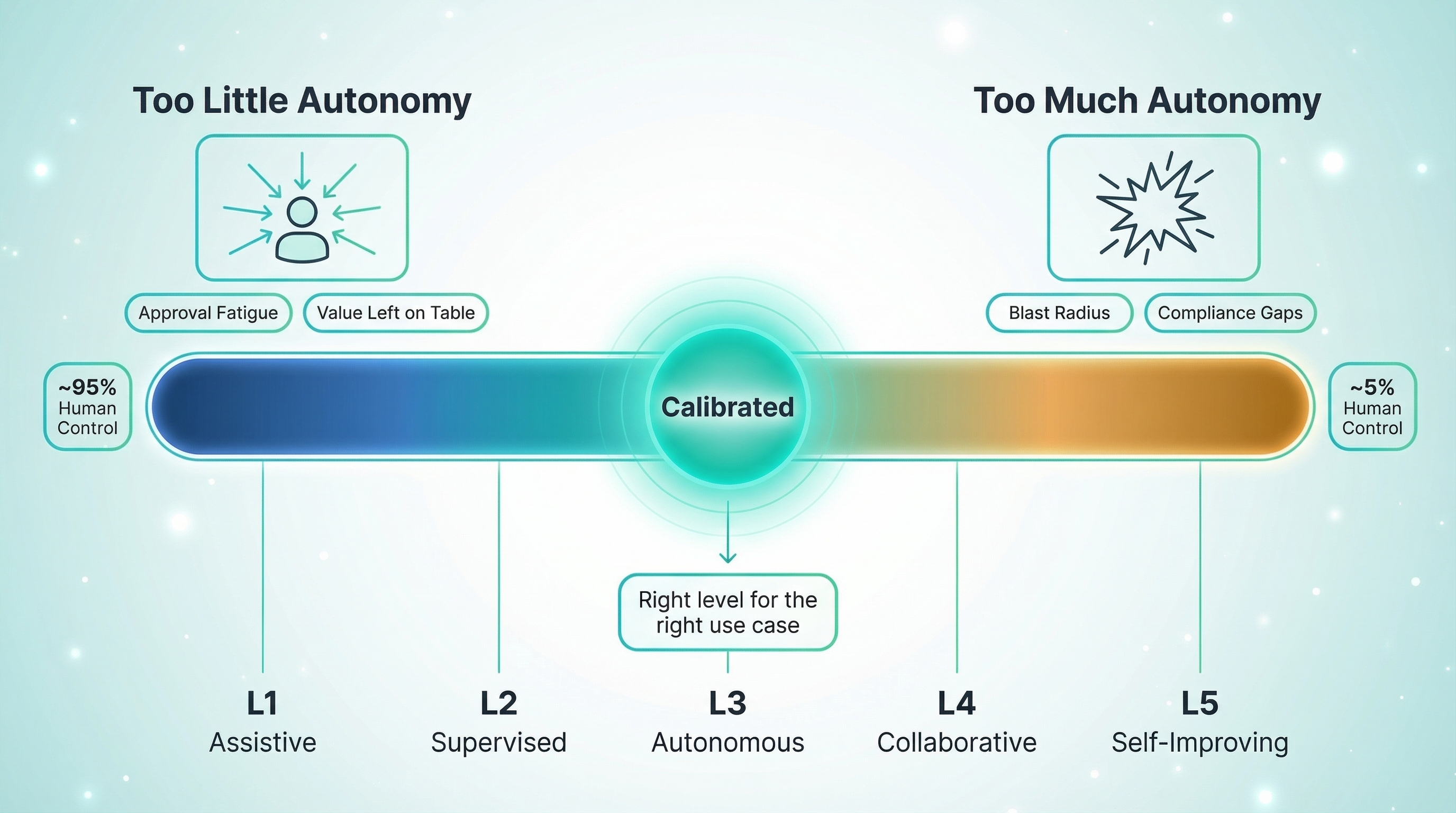
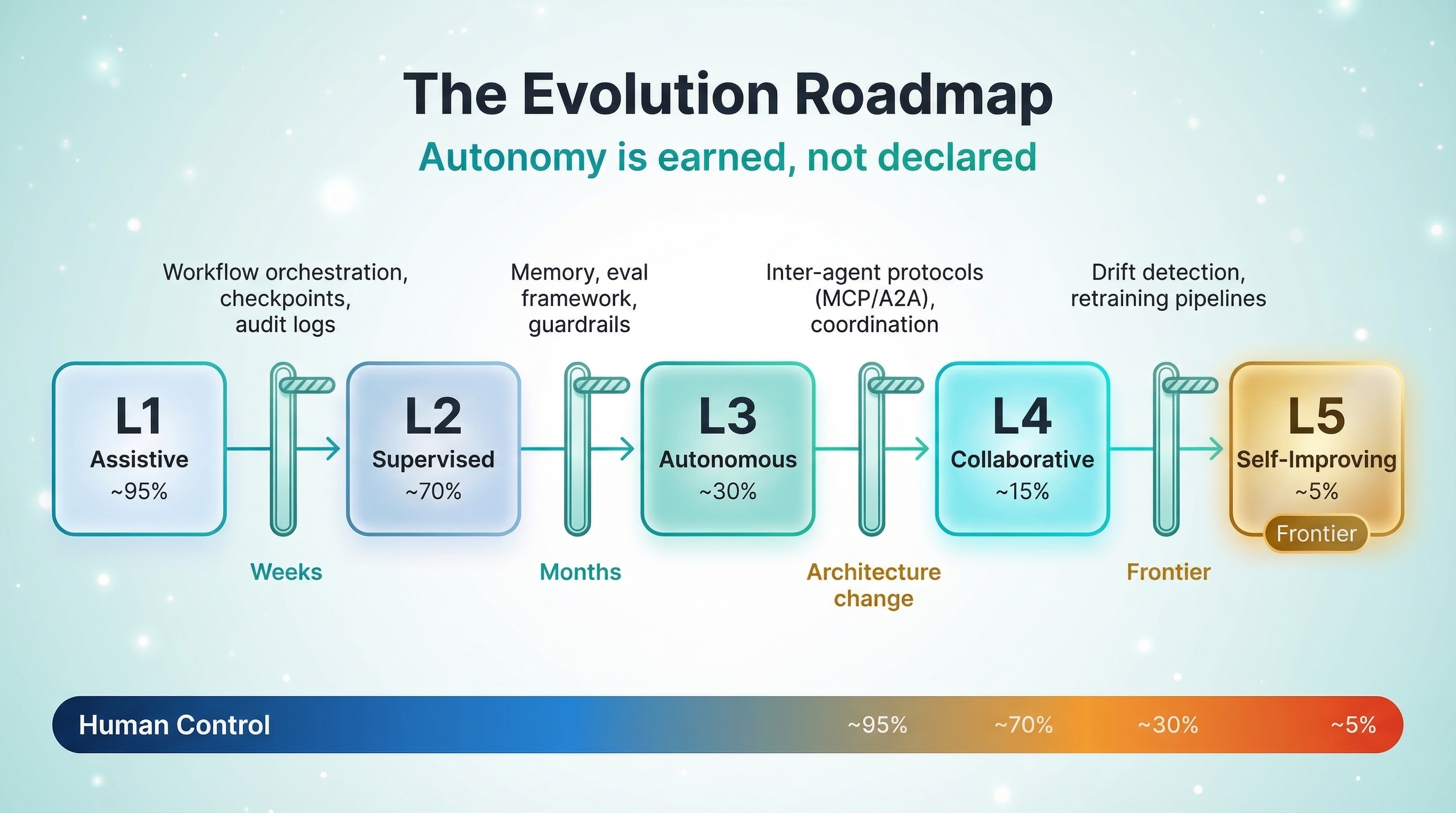
Five Levels of Agent Autonomy
Drawing from industry research — including frameworks from Anthropic, the Cloud Security Alliance, NVIDIA, and emerging work on self-evolving agents — here's a five-level model that maps autonomy to architecture patterns, human control, and real use cases.
To make this concrete, we'll walk through all five levels using a single domain: a hospital. Healthcare is the perfect lens because the stakes are high, the regulatory environment is real, and different tasks within the same organization genuinely require different autonomy levels.
L1: Assistive — Human Drives, AI Assists
Pattern: Request → Response. The human sends a prompt, the LLM reasons over it and generates a response — optionally calling tools like RAG retrieval, APIs, or databases along the way. There is no autonomous loop. No planning across steps. No memory carried between interactions unless the human explicitly provides it. Every action begins with the human and ends with the human reviewing the output. The model responds but does not initiate, and it never self-corrects or retries on its own. This is the pattern behind most chatbots, copilots, and AI assistants in production today.
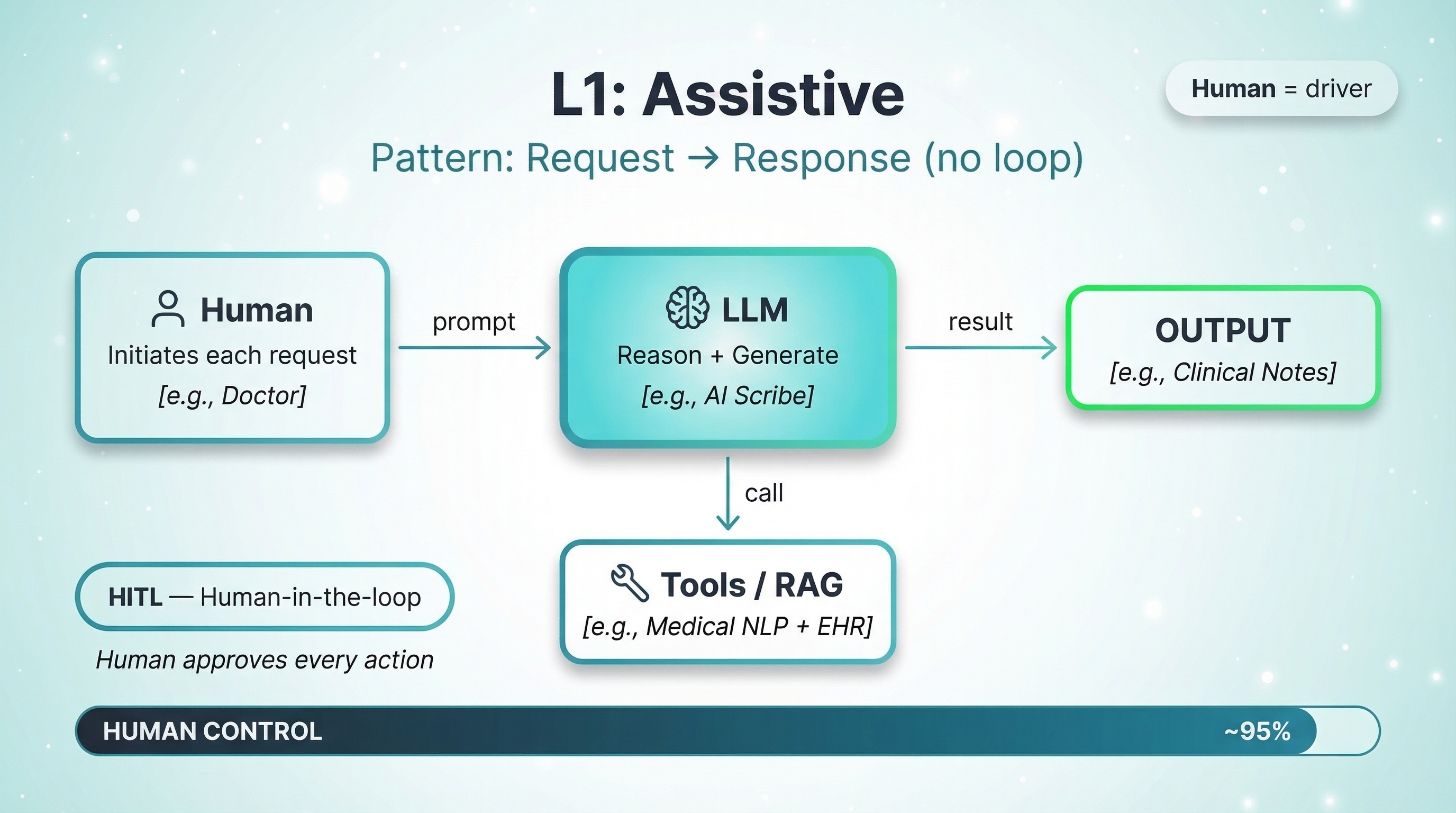
Hospital example: Clinical Documentation AI. The system listens to a doctor-patient conversation and drafts SOAP notes. The doctor reviews every word, edits, and signs.
Why can't this be L2? Because clinical notes become part of the legal medical record. NLP still misinterprets medical jargon, accents, and context. "Patient denied chest pain" versus "patient described chest pain" is one word that changes the entire clinical picture. No hospital's legal team will accept unsigned AI-generated documentation. The doctor must review every output.
What would unlock L2: Near-zero transcription error rates validated across thousands of encounters, regulatory acceptance of AI-assisted documentation, and malpractice insurance frameworks that cover AI-generated notes. None of these exist today.
Human control: ~95%. Stateless or basic multi-turn. Tools invoked per request. No autonomous planning or self-correction.
L2: Supervised — Orchestrated Pipeline, Human Checkpoints
Pattern: Orchestrated DAG with LLM nodes. The system is structured as a predefined directed acyclic graph — a workflow where each step is known in advance. At each node, an LLM handles the reasoning: interpreting inputs, calling tools, generating outputs. But the graph controls what happens next — which step follows which, where the workflow branches, and where it parallelizes. The LLM doesn't decide the flow; it executes within the flow. At designated checkpoints, a human reviews the output before the workflow proceeds. Common design patterns at this level include prompt chaining, routing, orchestrator-workers, and evaluator-optimizer loops. The DAG is the driver — not the LLM.
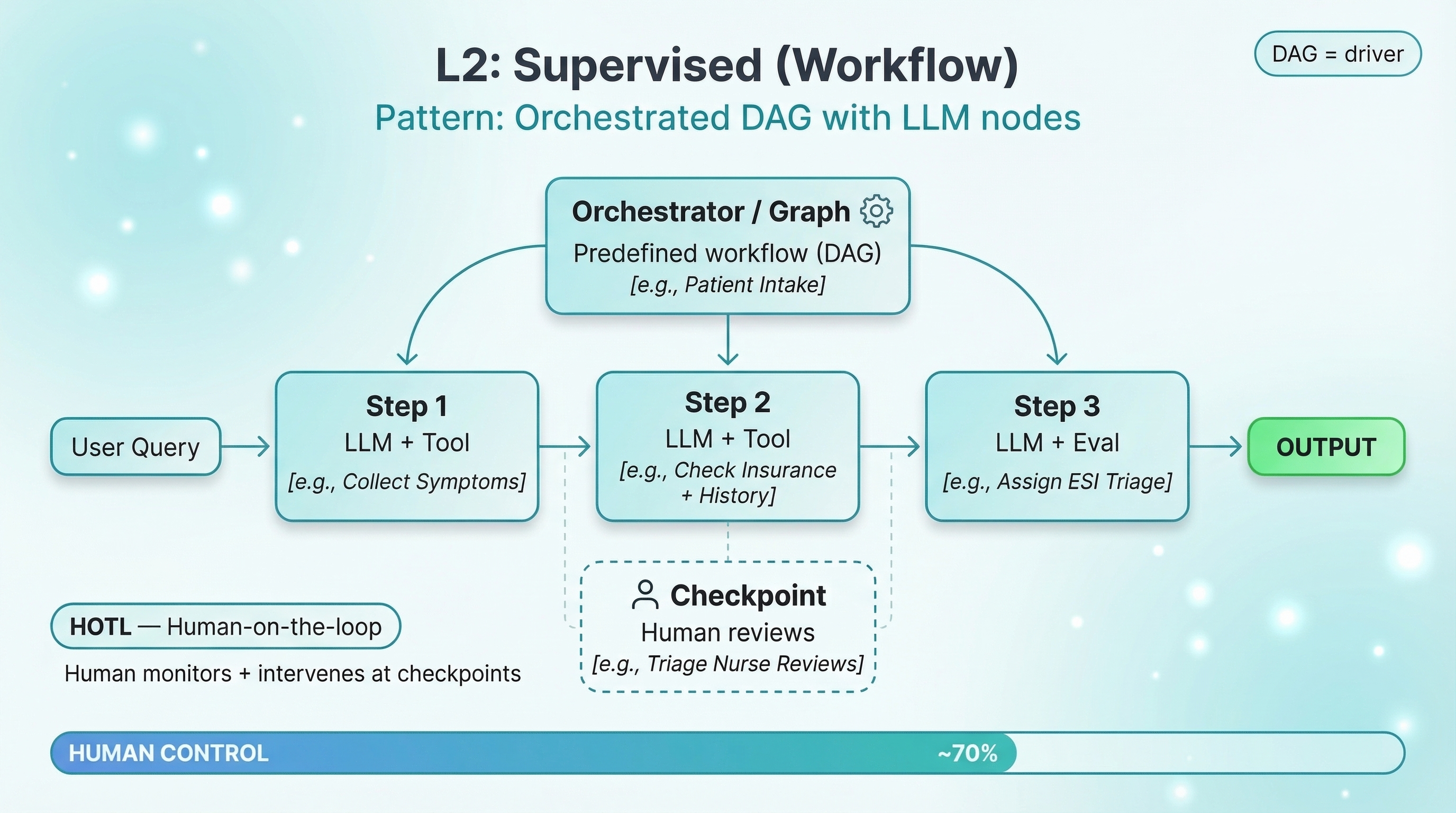
Hospital example: Patient Intake and Triage Routing. The system collects symptoms via a kiosk, checks insurance eligibility, pulls medical history, pre-fills forms, assigns an initial ESI triage level, and routes to the right department. A triage nurse reviews the routing decision before the patient moves.
Why can't this be L3? Because triage misclassification kills people. An ESI-3 patient miscategorized as ESI-5 waits hours instead of minutes. The system handles data gathering and initial scoring well — that's structured work. But the judgment call on edge cases — a patient presenting with "just a headache" who actually has a subarachnoid hemorrhage — requires clinical intuition that current models don't have. The nurse checkpoint isn't bureaucracy. It's the safety net for the 8-12% of cases where the initial triage score is dangerously wrong.
What would unlock L3: Validated triage accuracy above 95% across all ESI levels, including rare presentations. Liability frameworks for AI-driven triage. Real-time physiological data integration — vitals, not just self-reported symptoms.
Human control: ~70%. Design patterns include prompt chaining, routing, parallelization, and orchestrator-worker architectures.
L3: Autonomous — Human Sets the Goal, Agent Runs the Loop
Pattern: Goal → Autonomous Reason-Act Loop. The human provides a goal and a set of guardrails, then steps back. The LLM takes over — it reasons about what to do next (Plan), selects and executes tools (Act), evaluates the results (Observe), and decides whether to loop again or declare the goal met. There is no predefined graph dictating the steps. The LLM dynamically chooses which tools to call, in what order, and how to handle errors or unexpected results. It maintains persistent memory across steps, building context as it works. This is the ReAct and Plan-and-Execute pattern — the architecture behind most "autonomous agents" in production today. The LLM is the driver.
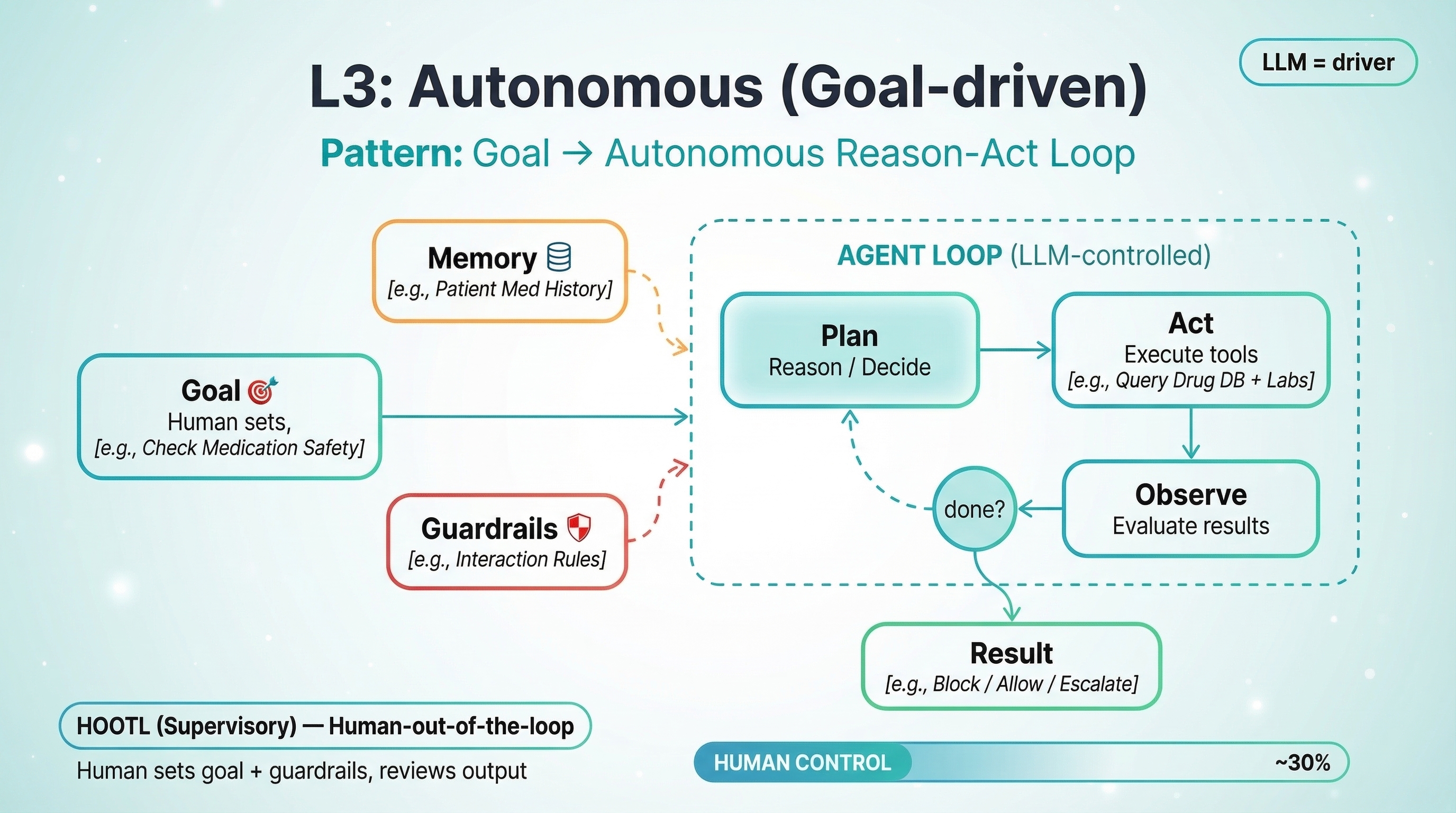
Hospital example: Medication Interaction Checking and Alerts. When a physician orders a medication, the system autonomously cross-references the patient's full medication list, allergies, lab results for kidney and liver function, weight, and genomic data if available. It doesn't just flag interactions — it blocks dangerous combinations outright, suggests alternatives with dosage adjustments, and only escalates genuinely ambiguous cases to a pharmacist.
Why does L3 work here when L2 wouldn't? Because the rules are well-defined — drug interaction databases are comprehensive — the consequences of missing an interaction are severe, and physician alert fatigue means humans were already ignoring over 90% of medication alerts anyway. The system is measurably better at this than humans. But it operates in a single domain with structured data. It can't coordinate across departments or weigh competing clinical priorities — like deciding that a dangerous drug interaction should be managed rather than blocked because the patient will die without both medications.
What would unlock L4: Cross-domain clinical reasoning capability and the ability to weigh tradeoffs that require judgment across multiple medical specialties simultaneously.
Human control: ~30%. ReAct and Plan-and-Execute patterns. Open-ended tool selection. Error recovery. Persistent memory. The LLM controls the loop — not a predefined graph.
In Production: The 90%+ alert fatigue stat is real. Studies consistently show physicians dismiss the vast majority of medication alerts because most are clinically insignificant. An L3 autonomous system that blocks only truly dangerous interactions and stays silent on the rest actually improves safety compared to an L2 system that alerts on everything and gets ignored.
L4: Collaborative — Human Sets the Mission, Agents Coordinate
Pattern: Coordinated Specialized Agents. Multiple agents — each with its own tools, memory, and reasoning loop — collaborate on a shared mission. A coordinator agent sits at the top, decomposing the mission into subtasks and delegating them to specialized agents: a planner that breaks down complex problems, an executor that calls APIs and runs code, a reviewer that validates quality, and on-demand specialists brought in as needed. The agents communicate through shared protocols like MCP and A2A, reading from and writing to shared or partitioned memory. The coordinator routes information, merges results, and resolves conflicts between agents. The system exhibits emergent capabilities — behaviors that arise from the collaboration that no single agent could produce alone.
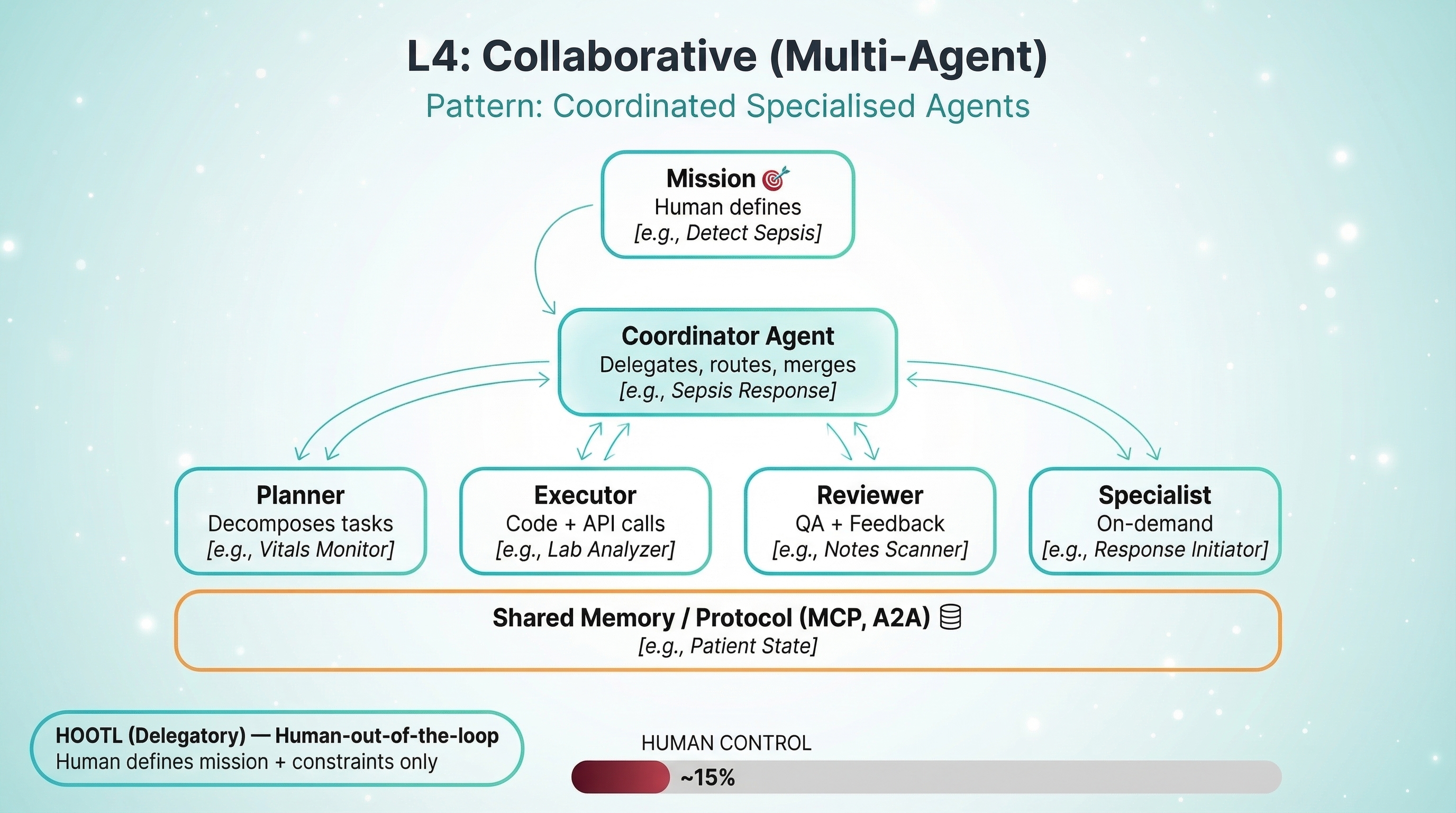
Hospital example: Sepsis Detection and Response Coordination. One agent monitors vitals continuously — heart rate variability, blood pressure trends, temperature patterns. Another watches lab results — lactate levels, white blood cell counts. A third tracks nursing notes for clinical observations like "patient seems confused." A coordinator agent synthesizes signals across all three streams. When sepsis probability crosses a threshold, the system autonomously initiates the sepsis bundle: orders blood cultures, starts IV fluids, pages the rapid response team, and alerts the attending physician.
The physician oversees and can override. But the system acts first — because sepsis mortality increases 7-8% for every hour of treatment delay.
Why can't this be L5? Because the system doesn't learn from outcomes to improve its own detection models. Its thresholds and protocols are set by humans. If a new sepsis biomarker emerges, or the patient population shifts — say, post-COVID inflammatory patterns that mimic sepsis — humans need to update the rules. The system executes a known playbook extremely well. It doesn't write new playbooks.
What would unlock L5: Validated continuous learning pipelines that can update detection models from patient outcomes without introducing drift. Regulatory approval for self-modifying clinical decision systems. Neither exists at scale today.
Human control: ~15%. Inter-agent communication protocols (MCP, A2A). Shared or partitioned memory. Delegation and agent-to-agent feedback loops.
In Production: The 7-8% mortality increase per hour of sepsis treatment delay is why L4's "act first, physician overrides" model isn't reckless — it's medically necessary. An L3 system that recommends and waits for approval would be the dangerous choice here.
L5: Self-Improving — Agents That Learn and Evolve
Pattern: Self-evolving loop. The inner agent loop — plan, act, observe — is wrapped by an outer evolution loop that closes the feedback cycle from outcomes back to strategy. After completing tasks, the system self-evaluates: what worked, what failed, and why. It then learns from those outcomes — updating its own models, rewriting its prompts, adjusting thresholds, or adding new tools to its repertoire. Finally, it adapts — modifying its strategies and applying them to the next round of tasks. This isn't fine-tuning by a human. The agent is autonomously improving how it operates through meta-learning and experience distillation. The human sets boundaries and monitors for drift, but the agent handles everything else — including improving how it handles everything else.
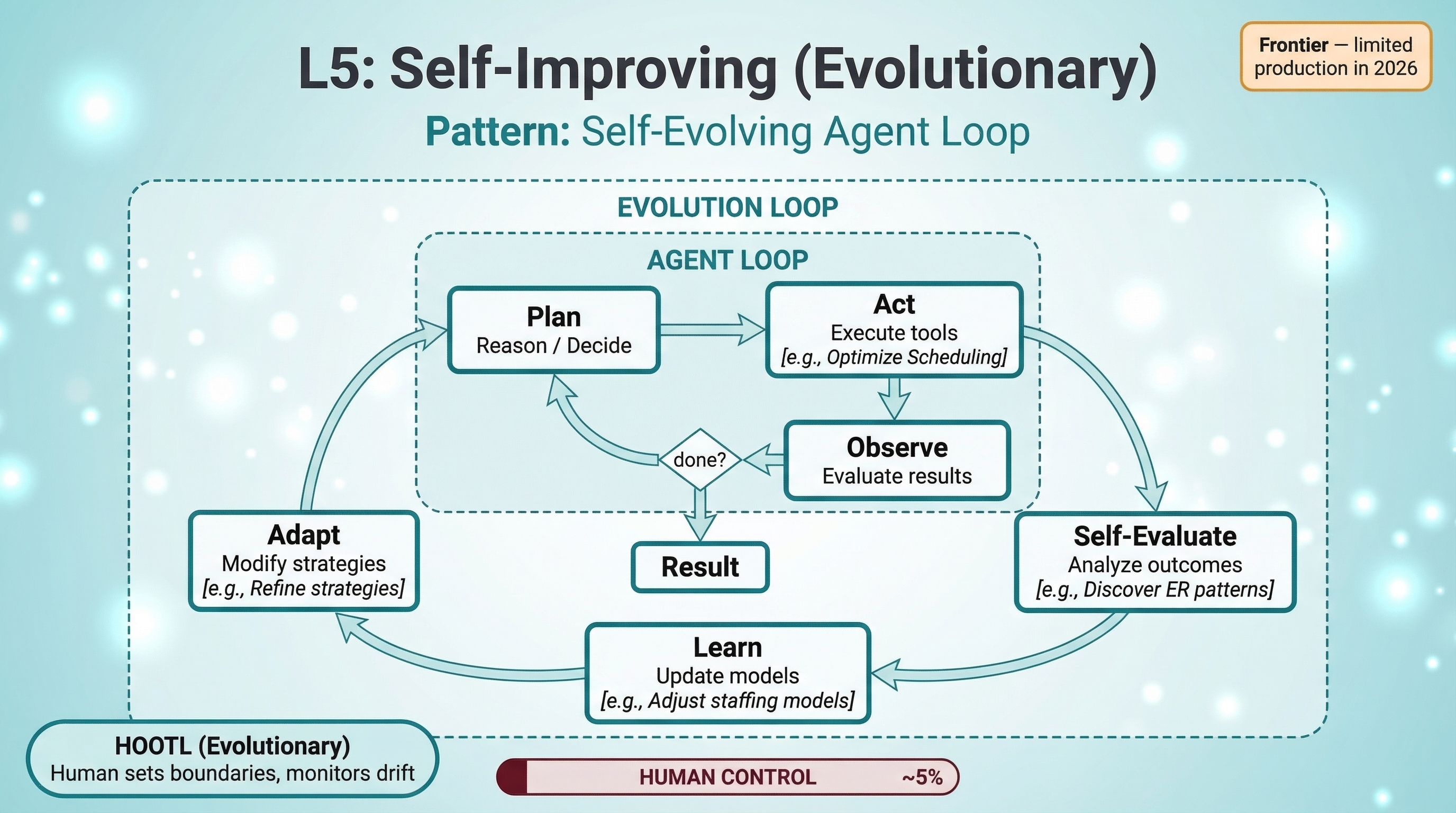
Hospital example: Hospital Operations Optimizer. The system manages scheduling, bed allocation, and patient flow. Over time, it discovers that patients admitted through the ER on Monday nights have 15% longer stays than Tuesday admissions. It traces the pattern to understaffed radiology on Monday nights, which causes diagnostic delays that cascade into longer stays. It proposes schedule adjustments, tests them, measures the impact, and refines its strategies based on real outcomes.
This is frontier. Almost no hospital runs this today — and for good reason. The technical challenge isn't the learning. It's the validation. How do you verify that a self-modifying system hasn't optimized for throughput at the expense of patient outcomes? How do you audit a scheduling strategy that no human designed? Regulatory frameworks for self-modifying clinical systems don't exist yet.
But the research is real. OpenAI published a cookbook on autonomous agent retraining. The EvoAgentX framework is building self-evolving agent ecosystems. MiniMax's M2.7 model ran over 100 autonomous development cycles, analyzing its own failures and rewriting code. A comprehensive survey maps the entire landscape of self-evolving agents.
Human control: ~5%. Sets boundaries, monitors drift, validates outcomes. The agent handles everything else — including improving how it handles everything else.
Understanding L5 matters even if you're building L2-L3 today. The architectural decisions you make now — how you structure memory, how you capture outcomes, how you evaluate performance — determine whether your agents can evolve later or hit a ceiling.
The Decision Framework: Choosing Your Starting Level
How do you decide which level a given use case should start at? Six measurable factors determine your autonomy ceiling.
| Factor | Favors Higher Autonomy | Favors Lower Autonomy |
|---|---|---|
| Error Cost | Easily corrected, low impact | Patient harm, financial loss, legal liability |
| Reversibility | Actions easily undone | Irreversible consequences |
| Regulatory Exposure | Internal processes, no compliance | HIPAA, SOX, FDA — audit trails required |
| Task Complexity | Well-structured, predictable | Ambiguous, multi-domain, requires judgment |
| Volume & Frequency | High-volume, repetitive | Rare, high-stakes decisions |
| Domain Stability | Stable, well-documented rules | Rules change frequently, edge cases common |
Notice that volume works in the opposite direction from most other factors. High-volume repetitive tasks actually favor more autonomy — because humans can't sustain quality at scale. This is exactly why the medication interaction system works at L3: the volume of alerts is too high for human review to be meaningful.
Here's how the same hospital maps three use cases to three different levels using these factors:
Clinical notes (L1): Error cost is high (legal record), reversibility is low (signed notes are permanent), regulatory exposure is heavy (medical records law), complexity is moderate. Every factor points to maximum human control.
Triage routing (L2): Error cost is life-threatening, but the structured data gathering part is low-risk. The workflow splits neatly: automate the data collection, checkpoint the routing decision. Classic L2 pattern.
Medication checking (L3): Error cost is high, but human alert fatigue makes the human the higher risk factor. Volume is massive. Domain is stable and well-documented. The factors tell you that full autonomy within a bounded domain is actually safer than human review.
The framework isn't prescriptive — it's a calibration tool. Two use cases in the same organization can legitimately require different autonomy levels. That's not a contradiction. That's good engineering.
The Evolution Playbook
You don't pick a level and stay there forever. Autonomy evolves as trust is earned and infrastructure matures. But the evolution is intentional, not accidental.
Level-up triggers. What metrics indicate you're ready to increase autonomy? Error rates dropping below a validated threshold. Human override frequency declining consistently. Coverage expanding to handle edge cases that previously required escalation. Confidence scores stabilizing across diverse inputs. If you can't measure these, you're not ready to level up.
Infrastructure requirements. Each level demands specific infrastructure that the previous level didn't need:
- L1 → L2: Workflow orchestration (DAG framework), structured checkpoints, audit logging
- L2 → L3: Persistent memory, evaluation framework, guardrails, error recovery loops
- L3 → L4: Inter-agent communication protocols (MCP, A2A), shared memory, coordination logic
- L4 → L5: Drift detection, outcome-based retraining pipelines, self-evaluation frameworks
The skip tax. Teams that try to jump from L1 to L3 — skipping the workflow orchestration layer entirely — consistently pay for it. They miss the checkpoint patterns, the workflow observability, and the audit trails that L3 depends on. It's like building a second floor without the first. The structure might stand for a while, but it's not something you want to bet patient safety on.
In Production: A realistic evolution timeline: L1 to L2 can happen in weeks — you're adding workflow structure around an existing assistant. L2 to L3 takes months of validation — you're removing human checkpoints, which means you need proof they're not needed. L3 to L4 is a significant architecture change — you're moving from a single agent to multi-agent coordination. L5 is aspirational for most teams in 2026, but the architectural groundwork starts at L3.
The Autonomy Audit
Here are five questions to run against your production agents right now. Not the autonomy level you designed — the one that's actually operating.
1. What's the actual human override rate? If it's below 5%, your humans might be rubber-stamping — you could be under-autonomous. If it's above 30%, the agent isn't ready for its current level.
2. Can you explain the agent's last 10 decisions? If you can't trace the reasoning, your observability isn't ready for the autonomy level you've deployed. Pull back or instrument better.
3. What's the blast radius of the agent's worst possible action? If you can't answer this in one sentence, you haven't scoped autonomy correctly.
4. Is the human checkpoint adding value or adding latency? If humans approve over 95% of actions in under 3 seconds, that's not oversight. That's liability with a job title.
5. What would trigger you to increase or decrease this agent's autonomy? If you don't have defined triggers, you're not managing autonomy — you're hoping. Define the metrics that earn a level-up and the thresholds that force a level-down.
Key Takeaways
- Agent autonomy is a spectrum you calibrate per use case, not a maturity ladder you climb. The same organization can — and should — run L1, L3, and L4 simultaneously for different use cases.
- Use the decision framework — error cost, reversibility, regulatory exposure, complexity, volume, and domain stability — to choose your starting level. Then define explicit triggers for evolution.
- Each autonomy level requires specific infrastructure. Skipping levels is more expensive than building them. The skip tax is real.
- L5 (Self-Improving) is the frontier. Understanding it now shapes how you architect L3-L4 for future evolution. Build for where you're going, not just where you are.
The Digixr Take
The art of agent autonomy isn't giving your agent more freedom. It's knowing exactly how much freedom each use case earns — and building the infrastructure to grant it responsibly.
The teams that master this calibration will outperform both the "automate everything" crowd and the "human-approves-everything" crowd. One moves fast and breaks things that shouldn't break. The other moves so slowly that the AI investment never pays off.
The art is in the middle. Start deliberate. Evolve intentionally. Measure obsessively. That's not caution — that's engineering.
What autonomy level are your production agents actually running at — and is it the right one? I'd genuinely like to hear your calibration stories. Find me on LinkedIn or X.