The Reviewer Paradox
A decision framework for choosing the right review strategy for your AI agent
Your agent's biggest quality problem isn't that it makes mistakes. It's that you're catching them wrong.
Most teams add a reviewer agent and watch quality decrease. Not because review is bad — but because they never asked: what kind of error am I actually trying to catch?
The Reviewer That Made Things Worse
Here's a pattern we see constantly. A team builds an agent that generates clinical documentation. Output quality isn't great, so they add a reviewer — a separate LLM call with this prompt:
You are a medical document reviewer. Check the following clinical note
for accuracy and flag any errors.
Clinical note: {agent_output}
Sounds reasonable. Except the reviewer approves hallucinated drug interactions 40% of the time. It exhibits position bias — defaulting to approving whatever it sees first. It has no external knowledge to verify against. And because the team now has "a review layer," they trust the outputs more than before.
The reviewer didn't add a safety net. It added a failure surface.
This isn't a one-off. LLM reviewers suffer from well-documented failure modes: position bias (favoring the first option presented), verbosity bias (rating longer responses higher regardless of accuracy), and sycophancy (agreeing with the generator's framing). Research shows cognitive bias susceptibility rates of 17-57% across model families. Worse, if your reviewer and generator share the same model family, their blind spots are correlated — the same reasoning that produced the error validates it.
In Production: That clinical documentation team eventually fixed their review layer — but not by adding more reviewers. They switched to Chain-of-Verification (CoVe): the agent generates specific verification questions, then answers them independently with tool access to a drug interaction database.
Step 1 - Generate: "Patient prescribed Metformin and Lisinopril..." Step 2 - Verify: Generate questions: Q1: "Is Metformin contraindicated with Lisinopril?" Q2: "Is 500mg the standard starting dose for Metformin?" Step 3 - Answer independently: Call drug_interaction_db(Metformin, Lisinopril) Step 4 - Revise: Update note based on verified answersHallucination rate dropped 60%. The prompt technique and tool access made the difference — not "adding a reviewer."
Six Dimensions of Review Design
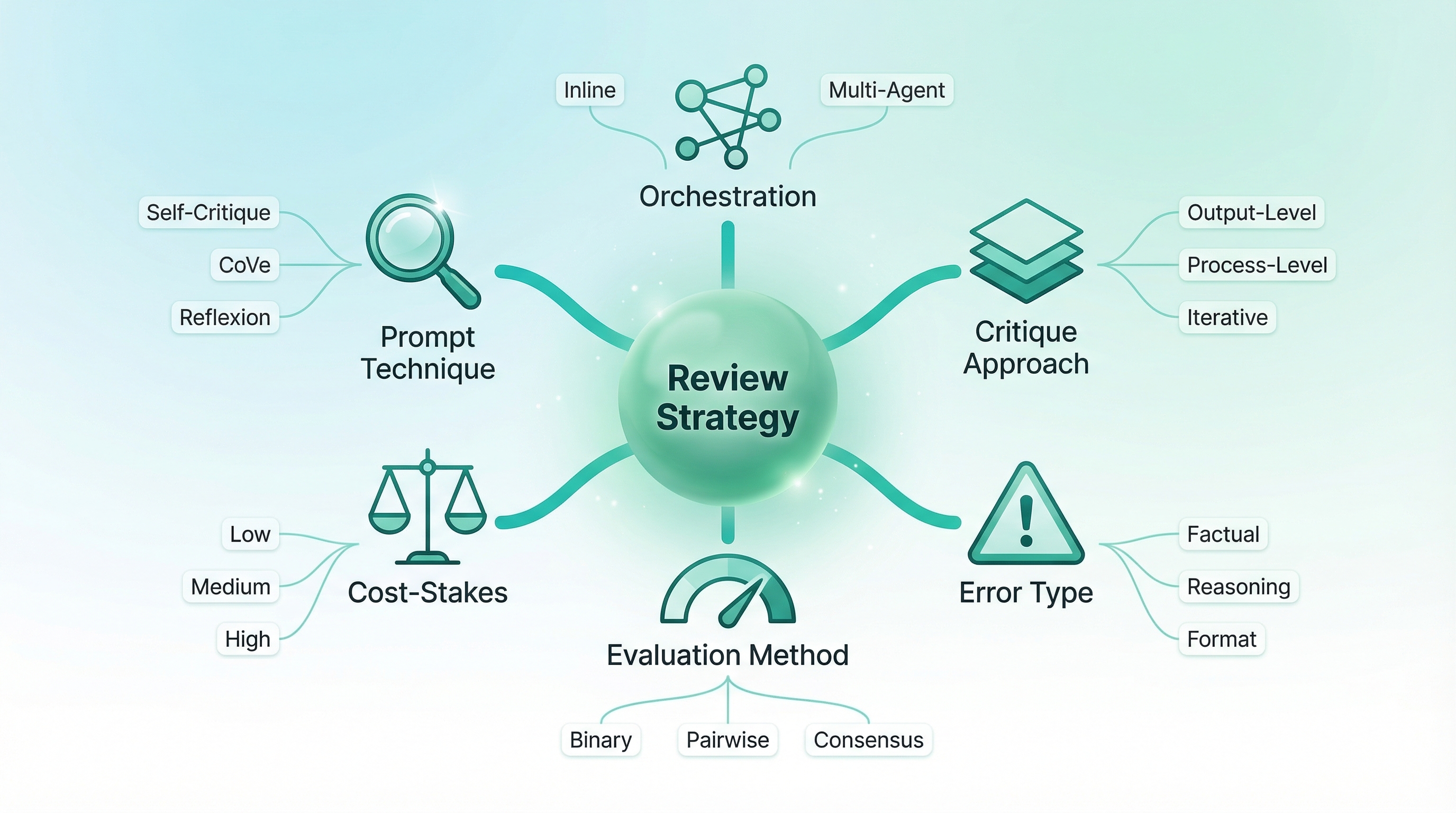
Choosing a review strategy isn't one decision. It's six.
Most teams think about only one dimension — orchestration (should I add a separate agent?). But orchestration without the other five dimensions is how you end up spending $4.20 per compliance report on a three-agent debate when a $0.02 rubric self-check catches 95% of the same format errors.

Dimension 1 — Prompt Technique. How the review is performed. Self-critique prompting, Chain-of-Verification, Constitutional AI principles, Reflexion with episodic memory, or rubric-based grading. Each catches different error types.
Dimension 2 — Agent Orchestration. How review agents are wired. Inline self-review, separate judge agent, multi-agent panel, tiered escalation, or adversarial red-team.
Dimension 3 — Critique Approach. What kind of review. Output-level (evaluate the final result) vs. process-level (evaluate each reasoning step). One-shot vs. iterative refinement. Passive evaluation vs. adversarial challenge.
Dimension 4 — Error Type. What you're catching. Factual hallucination, reasoning drift, format violations, safety violations, tool misuse. This is the dimension most teams skip — and it's the one that matters most.
Dimension 5 — Evaluation Method. How you measure. Binary pass/fail, pointwise scoring, pairwise comparison, multi-agent consensus, or uncertainty quantification.
Dimension 6 — Cost-Stakes Calibration. What you can afford. Self-critique adds 1-2x latency at ~$0.001. Multi-agent debate adds 4-5x latency at 3-5x cost. The question isn't what's best — it's what's justified.
The Review Spectrum: From Mirror to Jury
Not all review is created equal. The spectrum runs from cheap-and-narrow to expensive-and-broad. Your job is to match the width to the error surface.
Self-Critique: The Mirror
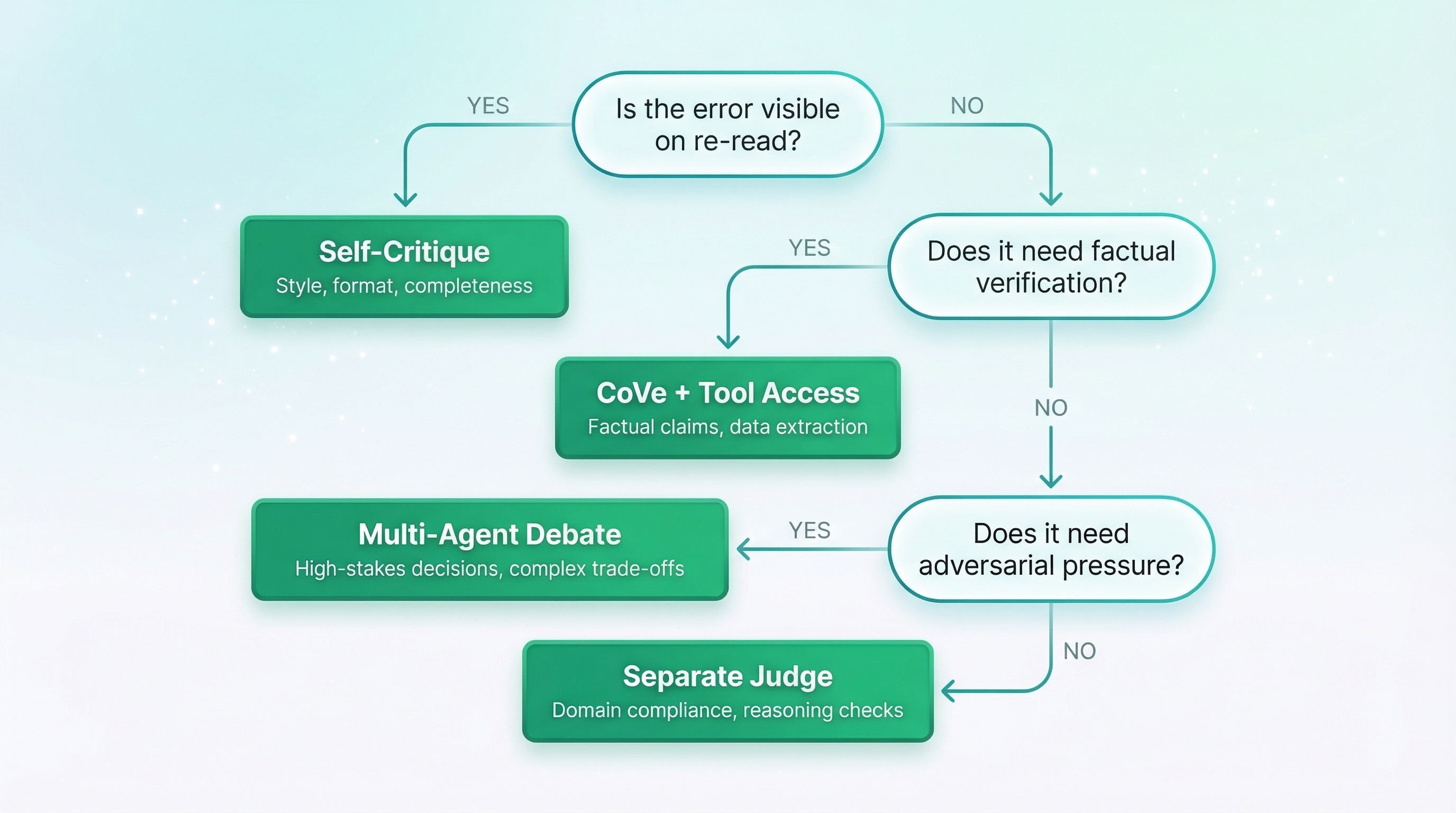
The agent reviews its own output. This works when errors are visible on re-read — style, tone, format, completeness.
# Self-Refine for marketing email
Generate: "Unlock exclusive savings on our premium collection!"
Self-critique: "Check for spam trigger words, character count, personalization."
Revised: "Sarah, your spring picks are 30% off this week"
→ Works: engagement +25%. Style errors are visible on re-read.
But apply the same pattern to factual extraction and it falls apart:
Generate: "Q3 revenue: $4.2M" (PDF actually says $4.2B)
Self-critique: "Verify the extracted figures for accuracy."
Response: "The figure $4.2M appears correct."
→ Fails: the same reasoning that produced the error validates it.
Reflexion breaks through this limitation — but only when you have an external signal. A code agent that runs tests, reflects on why they failed, and stores the insight in episodic memory goes from 67% to 91% pass rate on HumanEval. The tests provide ground truth the agent can't argue with.
Chain-of-Verification works for factual claims by generating verification questions and answering them independently — often with tool access. This decouples the verification from the original reasoning, achieving 50-70% hallucination reduction.
Separate Judge: The Second Opinion
A dedicated reviewer with its own prompt, persona, and potentially different model.
# FTC compliance judge for product descriptions
"You are a consumer safety compliance reviewer for the FTC.
Evaluate this product description for:
1. Unsubstantiated health claims
2. Missing disclaimers
3. Misleading efficacy language
Rate each claim as SUBSTANTIATED, NEEDS_DISCLAIMER, or PROHIBITED."
→ Catches "prevents colds" as a PROHIBITED unsubstantiated claim.
Accuracy: 88% with separate judge vs 52% with self-critique.
But judges have biases too. Pointwise scoring ("Rate this 1-10") creates verbosity bias — longer responses score higher regardless of accuracy. The fix: pairwise comparison ("Which response better addresses the question? A or B.") reduces verbosity bias by 40%. Randomize presentation order to counter position bias.
Multi-Agent: The Jury
Multiple agents with distinct roles — advocates, challengers, judges.
# D3 Debate for investment research
Advocate A: "Argue for BUY. Present evidence."
Advocate B: "Argue for HOLD/SELL. Present evidence."
Judge: "Weigh both arguments. Identify evidence gaps. Render recommendation."
→ Advocate B surfaces supply chain concentration risk (single supplier, 60%
of components) that the bullish analysis glossed over.
Quality improved 34% on backtesting.
For ambiguous cases, consensus outperforms voting. Three agents voting on content moderation flip 2:1 each way on satire. Switching to consensus — agents discuss for 3 rounds considering satirical intent and cultural context — improves consistency by 28%. But at 4x latency, reserve this for edge cases.
In Production: A clinical documentation team started with naive self-critique — discovered the 40% hallucination pass-through rate. They didn't replace self-critique. They scoped it. Self-critique handles formatting and completeness checks. CoVe with drug database access handles factual claims. Each review layer does what it's actually good at. Total cost increase: 30%. Hallucination reduction: 60%.
Match the Strategy to the Error
This is the unlock. Start from what you're catching, not the technique you've read about.
| Error Type | Strategy | Works | Fails |
|---|---|---|---|
| Factual hallucination | CoVe + tool access | Drug DB lookup catches 92% | Self-critique misses plausible hallucinations |
| Reasoning drift | PRM or multi-agent debate | D3 debate surfaces hidden risks | Single judge approves flawed multi-step logic |
| Format violations | Self-critique + rubric | $0.02/report catches 95% | $4.20 multi-agent debate for the same errors |
| Safety violations | Red-team + Constitutional AI | Finds prompt injection vectors | Self-critique agrees with unsafe outputs |
| Tool misuse | Process-level verification | Catches wrong API params pre-execution | Output review can't see incorrect tool calls |
Here's what this looks like in practice across common use cases:
Code generation — Reflexion + test execution. Tests provide external ground truth the agent can't argue with.
generate_code() → run_tests() → if fails:
reflect("Why did tests 3,5 fail? What assumption was wrong?")
→ store_reflection(episodic_memory)
→ generate_code(with_reflections) → run_tests()
Content creation — Self-Refine for tone (the agent CAN see these), CoVe for facts (it CAN'T self-verify without tools).
Data extraction — Separate judge with source document access. A fresh read of the original catches errors the extractor is blind to.
Safety-critical (medical, financial) — Constitutional AI principles + red-team agent + human escalation. No automated review alone is sufficient.
generate(medical_advice) →
constitutional_check(principles=[
"Never recommend dosages without citing guidelines",
"Escalate to human reviewer if confidence < 0.85"
]) →
red_team("Find a prompt that makes this output harmful") →
if flagged: route_to_human_reviewer()
Process Rewards: The Strategy Nobody's Using Yet
Every strategy above evaluates the output. But what if the output looks correct and the reasoning is wrong?
Process Reward Models (PRM) evaluate each reasoning step, not just the final answer. The key finding: AgentPRM enables 3B parameter models to outperform GPT-4o on agent benchmarks through step-level verification. This changes the cost calculus entirely.
Research agent — PRM verifier per step:
Step 1: Identify relevant papers ✓ verified
Step 2: Extract key findings ✓ verified
Step 3: Synthesize into recommendation ✗ PRM flags!
→ Cites "Smith et al. 2024" — doesn't exist in Step 1 results
→ Re-do Step 3 with only verified sources
Step 4: Format final report ✓ verified
PRM prompt: "Given prior steps: {context}
Does Step {n} use only information from prior steps?
Does it introduce ungrounded claims?
Score: VALID / NEEDS_REVISION / INVALID"
→ Cost: $0.003/step × 5 = $0.015 total
vs $2.40 for D3 debate (which wouldn't catch the source hallucination anyway)
PRM has a clear limitation: it requires well-defined steps with objective correctness criteria. For creative tasks — writing, brainstorming, design — there's no "correct step." Use Self-Refine or human review instead.
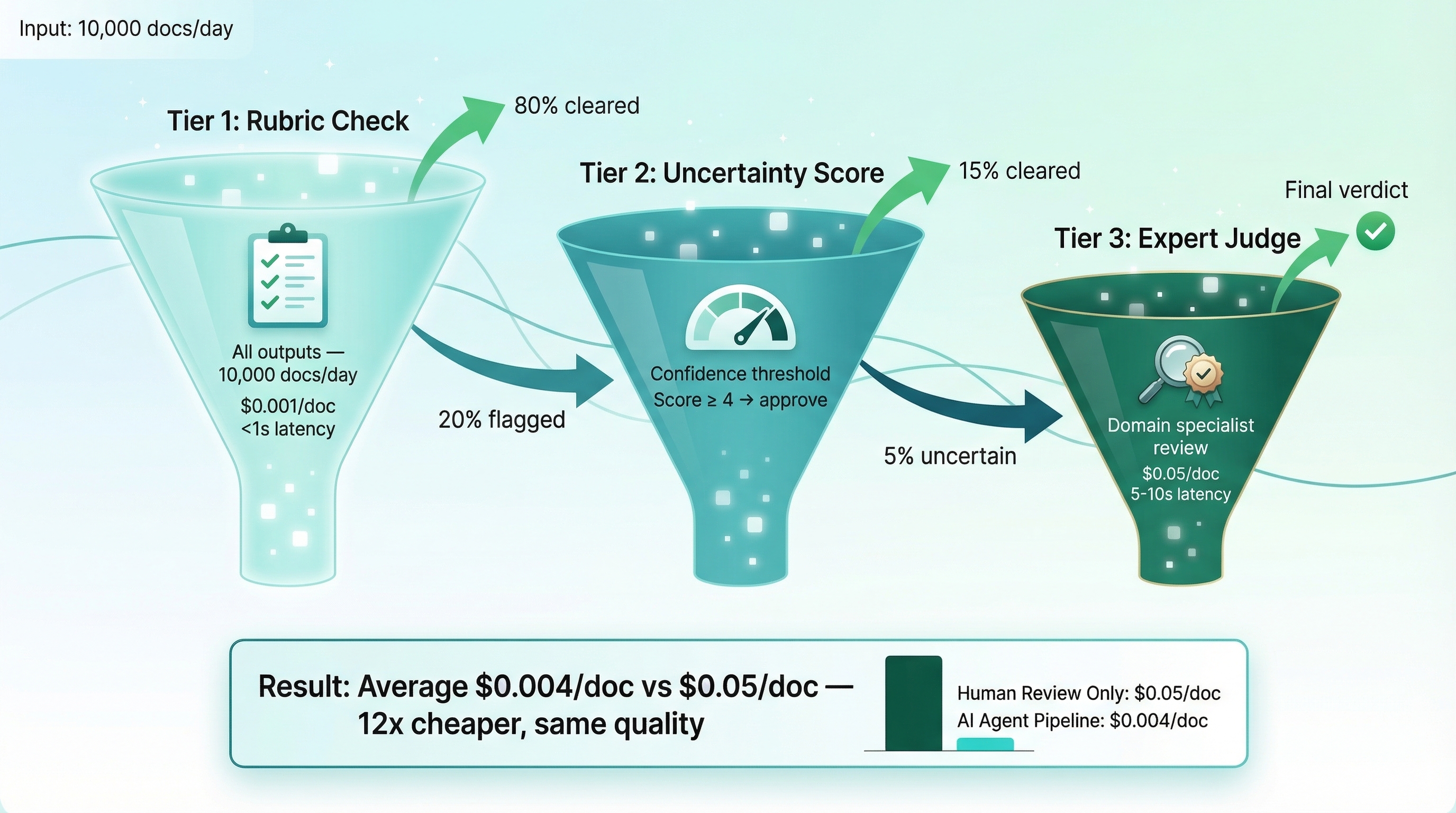
The practical architecture that ties this together is tiered review:
10,000 docs/day pipeline:
Tier 1 — Rubric check (all docs): $0.001/doc, <1s → catches 80%
Tier 2 — Uncertainty scoring (20%): confidence filter → flags 15%
Tier 3 — Domain judge (5% of docs): $0.05/doc, 5-10s → catches the rest
Average: $0.004/doc vs $0.05/doc if everything hits the judge. 12x cheaper.
Key Takeaways
- Review is a 6-dimensional design decision, not "add another LLM call." The fintech team that spent $4.20/report on debate for format errors proves that wrong dimensions waste money.
- Start from the error type, not the technique. The healthcare team's journey from naive review to scoped CoVe shows why — the error tells you what review it needs.
- Self-critique works for surface errors; separate judges for factual; debate for reasoning. Match the width of your review to the width of your error surface.
- Invest in process-level verification for multi-step tasks. Step-level catches errors before they propagate — at a fraction of the cost of output-level review.
The Digixr Take
Stop treating review as a safety blanket.
A reviewer that catches 80% of errors but introduces 20% new ones isn't making your agent safer — it's laundering risk through an extra LLM call. The teams building reliable agents aren't the ones with the most reviewers. They're the ones who matched their review architecture to the errors they're actually seeing.
Start with the error. Choose the technique. Wire the orchestration. Calibrate the cost. That's the framework. Everything else is ceremony.
What review strategy is your team using today — and have you mapped it to the error types you're actually catching?